Evaluation
Pre-Workshop Survey
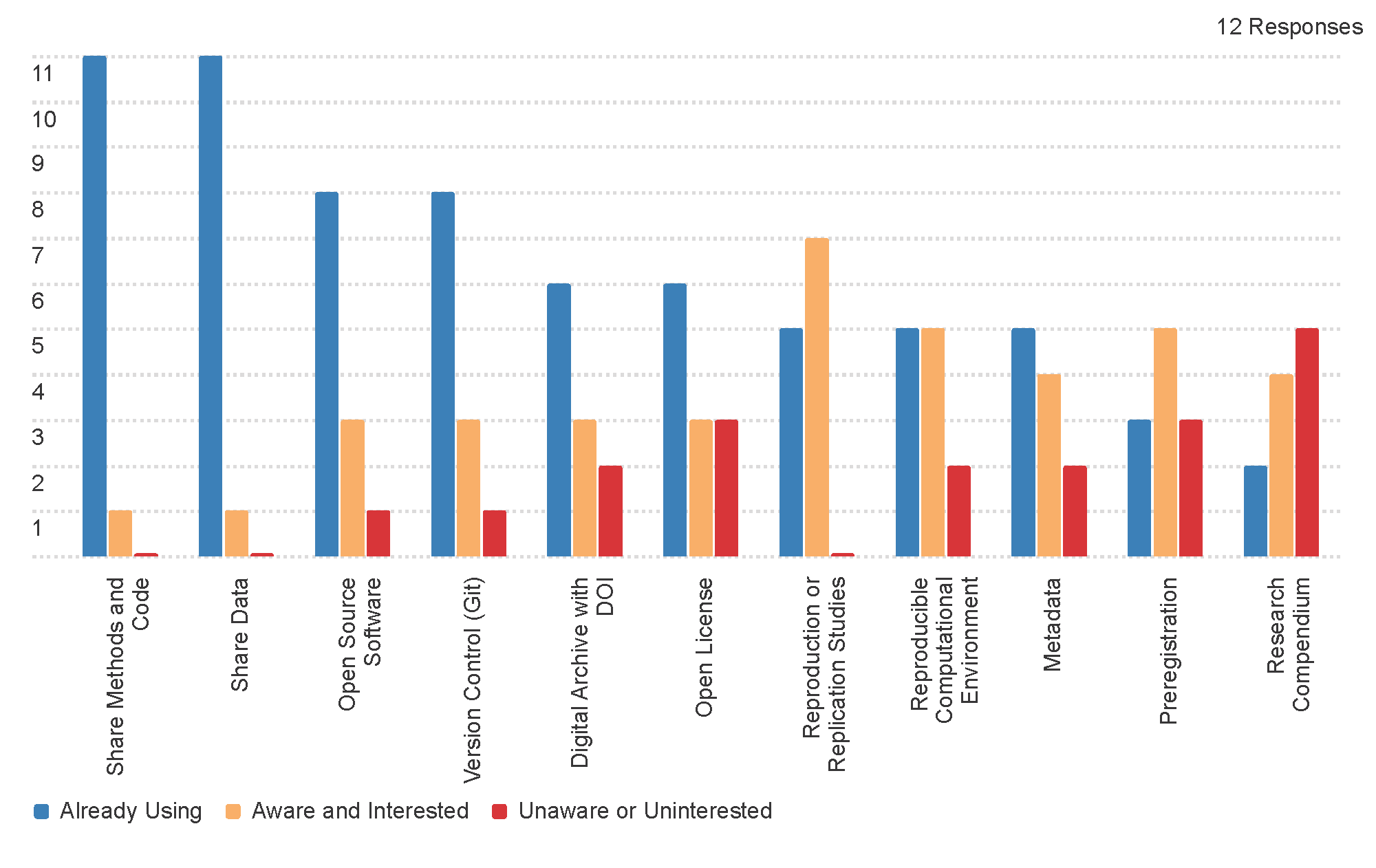
The graph above shows results from a pre-workshop survey of participants’ familiarity and experience with reproducible and replicable research practices. The practices that most participants were already using are sorted to the left of the x-axis. The y-axis is the number of participants. The greatest knowledge gaps were in:
- research compendiums: organized collections of all the files and information required to reproduce a study, including data, code and procedures, metadata, and ideally, computational notebooks.
- preregistration: writing and committing public records of analaysis plans prior to exploring and analyzing data
- open license: intellectual property license permissive of copying and redistributing the components of a study
- digital archive with DOI: a long-term archive that assigns a persistent unique identifier (DOI) link to research content, e.g. OSF, Figshare, Harvard Dataverse, etc.
Compared to previous workshops, this group of workshop attendees was already more engaged with and aware of reproducible and research practices.
Post-Workshop Survey
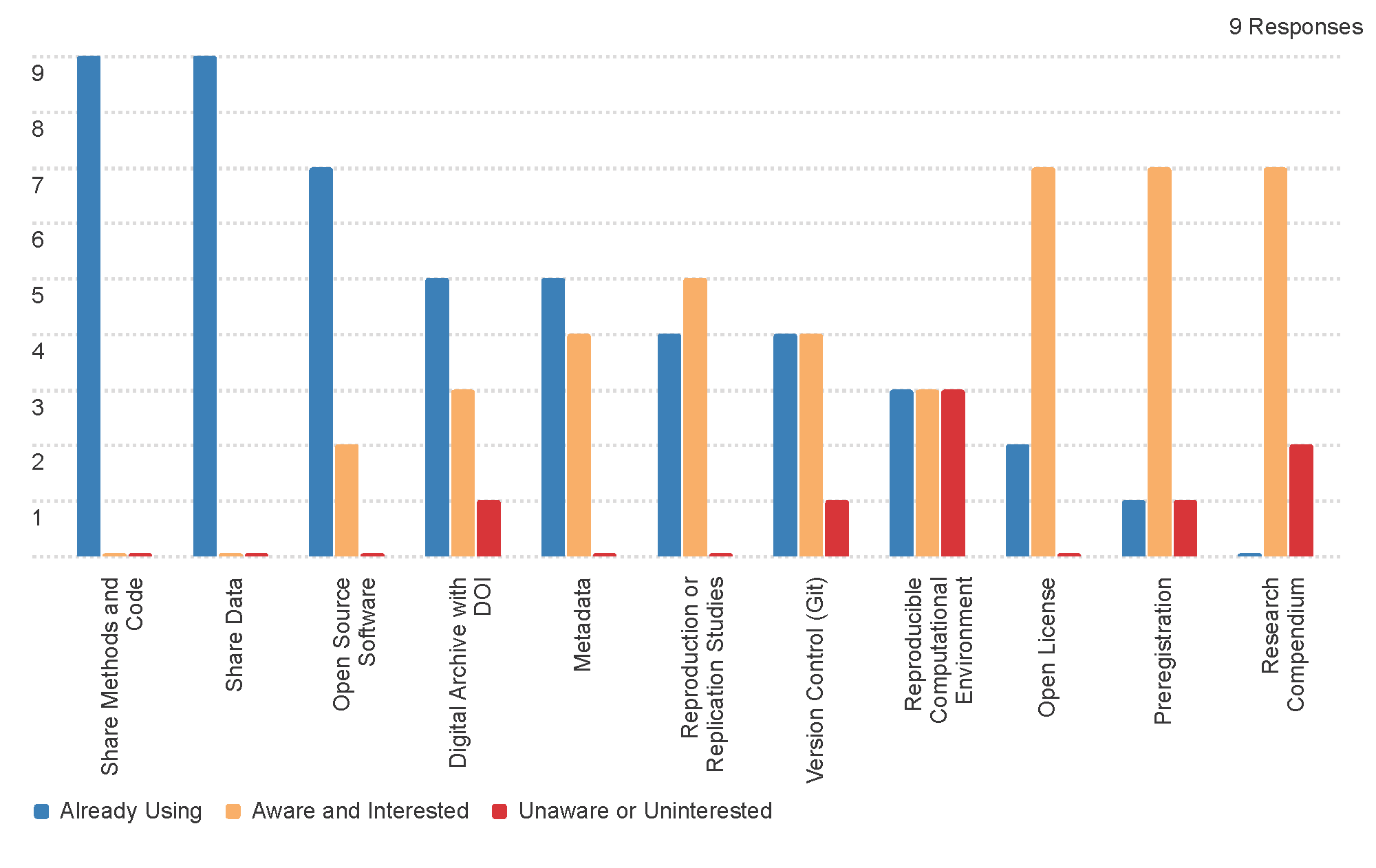
The post-workshop survey shows movement from the unaware or uninterested category into the aware and interested category, demonstrating increased awareness and interested in a greater breadth of R&R practices.
One practice shows the opposite:
- reproducible computational environment: Have researchers have shared detailed information about open-source software packages and versions requried to reproduce their work? Even better, have they codified, packaged, or publically shared the computational environment using technologies like renv, groundhog, conda environment files, Binder, Docker, JupyterHub, etc.
In our experience attempting to reproduce other researchers’ work, we have found this element of reproducibility to be consistently overlooked. It is one of the most common and frustrating barriers to overcome in computational reproductions. In this particular workshop, we were de-emphasizing particular technical challenges with computational reproducibility in favor of a broader conversation about R&R across the liberal arts curriculum. This result may indicate some participants realizing through presentations and discussions that they are not sufficiently aware of computational environments in R&R, and the workshop did not provide enough knowledge on this practice to improve outcomes.
We could not expect any movement from the aware and interested category into the already using category for this workshop, because the workshop did not devote time to practical training in or implementation of particular R&R practices.
Improvements
We asked: Do you have any suggestions for improving the workshop or future outreach on reproducibility and replicability?
Four participants replied with suggestions to:
- Provide more pre-workshop materials and preparation time.
- Discuss how to implement R&R broadly across curricula, including fields that are not as data-intensive
- Broaden representation of institutions and disciplines
- Suggest or discuss possible deliverables earlier
- Clarify the meaning of metadata in the context of open and reproducible science
Qualitative Outcomes
We asked: How have your knowledge or perceptions of open and reproducible research practices changed as a result of the workshop?
Seven participants replied, with responses appreciating:
- learning new developments/broader landscape in open science
- much stronger sense of what others are doing, what they care about, and how they approach R & R in a liberal arts context.
- inter-disciplinary focus
- what is appropriate for courses more/less focused on quantitative analysis
- more familiar with certain practices that are less widespread in my own field
- different ways schools approach support for quantitative data analysis
and looking forward to:
- implementing many ideas to implement in teaching
- specific tools and steps that feel more feasible to adopt in my work and my classes
- plans to move my institution forward on reproducibility